What's That Noise?! [Ian Kallen's Weblog]
 Wednesday June 22, 2005
Wednesday June 22, 2005
live8 Web site lauches galore this week... the release of the Technorati redesign has been joined by Technorati Live8.
In an effort to raise awareness for African debt relief, Bob Geldof and all the usual suspects are putting on a load of concerts. And Technorati will you bring you the blogosphere's coverage.
( Jun 22 2005, 05:31:28 PM PDT ) Permalink
Monday May 30, 2005
Annotation Shmannotation Among the most interesting things that the blogospere has demonstrated in the last few years is its capacity as a medium for distributed conversation and meme propagation. Implicit and spontaneous communities coalesce and atrophy and the web has become the transport for peer-to-peer publishing.
A post showed up recently on Ideant, Facilitating the social annotation and commentary of web pages that drew me in but then turned me off. It's a review of working or proposed systems that use anchor/name tags, rdf, autolink-ish page transformations and browser plugins for annotation systems. There's a lot of great stuff there about eliminating the distinction between authors and respondents, filtering, open infrastructure, and so on (read it)... but I can't figure out the emphasis on annotation.
The post goes badly astray with this requirement for distributed textual discourse:
Hypertextual granularity. Discourse participants are able to hypertextually annotate every fragment of an online text, instead of having to refer to online texts as wholes which cannot be annotated.Every fragment? If I want to identify a particular sentence or two as part of a conversation, I'd be more inclined to simply cite and respond:
<blockquote cite="http://ideant.typepad.com/ideant/2005/05/facilitating_th.html#challenges">
Discourse participants are able to hypertextually annotate every fragment of an online text
</blockquote>
Well, that level of granularity is an edge case requirement
In fact, the ability to address every fragment of text is not a requirement for dispersed discourse. That all of these systems reviewed to support annotation are so intrusive on the author is indicative of how problematic this requirement is.
HTML's intrinsic support for linking, anchoring and citing provide a sufficient medium for binding together dispersed discourse. Browser plugins? Your blog is your platform for citation. Parallel universes (rdf) or structural modifications to make everything "citable" beyond the author's original intention smells like gratuitous complexity. Let the web be the web.
annotation social software blogging
( May 30 2005, 10:30:55 PM PDT ) PermalinkOne Chance Only for Mozilla Mail to Thunderbird Migration? A family member had mistakenly hit "Cancel" when firing up Thunderbird for the first time when prompted to import from Mozilla/Netscape 7. Astonishingly, the Thunderbird developers don't make that option available from that point forward. You can import from Eudora, Outlook (yea, this is a Windows box) or Navigator 4 but there's no option to import from Mozilla. Must be graduates from the School of Masochistic User Interfaces.
Assuming the user (or you if this is your problem) hasn't starting using the Thunderbird installation so the profile can be safely, here's the work around:
- [Start] menu
- "Run"
- type "thunderbird -p" and return
The Profile Manager comes up (old school Navigator-style) and there's a profile named "Default" selected already- hit "Delete Profile"
- hit "Delete Files"
- Now go back and start Thunderbird, the option to import from Mozilla is there
More details and scenario options are available at mozillaZine
( May 30 2005, 01:14:41 PM PDT ) Permalink
Sunday May 29, 2005
Technorati Japan The lift of weightlessness and the carthasis of a product release is one of the great rewards of ushering a project to fruition.
So it is with this pleasure that I bring your attention to the beta release of Technorati Japan. This is a true eat-your-own-dogfood story; the localizable code base behind the website is built with all searches as clients of the Technorati API, woof. Coinciding with this release is Joi's inaugural post to the Technorati Japan Blog. To toast the efforts of my colleagues at Technorati and the Tokyo team @ technorati.jp, I raise my virtual sake glass!
And if you read Japanese, we hope for your feedback and that you enjoy the site!
( May 29 2005, 11:45:27 AM PDT ) PermalinkThwarting Spam With GMail and Procmail I've been self hosting my mail for almost 10 years now and I'm not about to quit. But the growing ineffectiveness of SpamAssassin has made me consider it. While SpamAssassin was catching a lot of spam, at least as much was still getting through. It'd really gotten a lot worse lately. I probably could have done more with it (and I may still dig deeper into how to configure SpamAssassin to work better for me) but I was intrigued by the idea of using a web mail host as a pass-through service to do it for me.
I've used GMail since last summer but really haven't had a whole lot need for it... it's a nice place to subscribe to mailing lists from. When I'd read Using Gmail as a Spam Filter a while back it intrigued me but the idioscyncrasies of procmail and qmail made it seem like more of project than I'd wanted to undertake (yea, yea... one of these days I'll migrate to postfix but I have a lot of legacy ezmlm stuff running, I need to figure out how to migrate that to mailman or something).
Well since I had a ton of GMail invites sitting around, I invited myself to create another account (one that no spammers will know the name of, I hope... we'll call it gmail.username for now). I followed the GMail side of the instructions at the site above, e-z nuf. And then I got to the stuff on my server. This is what I ended up doing in my procmailrc to get procmail to forward a message and accept it again once GMail took its turn on it:
:0 * ! ^X-Forwarded-For: gmail.username@gmail.com my.username@my.domain.com | /usr/bin/formail -R Delivered-To X-Delivered-To | \ /usr/sbin/sendmail -oi gmail.username@gmail.comI probably could've used qmail-inject instead sendmail but whatever, this works. So what's up with the pipe to formail -R Delivered-To X-Delivered-To?
Well, without it qmail got very grouchy. Well, grouchy in that inimitable qmail'ish way:
Hi. This is the qmail-send program at my.domain.com. I'm afraid I wasn't able to deliver your message to the following addresses. This is a permanent error; I've given up. Sorry it didn't work out. <my.username@my.domain.com>: This message is looping: it already has my Delivered-To line. (#5.4.6)OK, so qmail's loop detection worked a little too well for me; I worked around it by munging the Delivered-To line.
My vindication came in the hours that followed as dozens of pieces of junk messages ended caught by GMail's spam detection and the mail that I wanted got through to me on my longstanding but spam-threatened email address.
Warning: if you want to email me something without Google knowing about it (i.e. say you have a business proposition that is a "google killer"), ask me for some alternate methods.
spam email gmail qmail procmail
( May 29 2005, 01:02:26 AM PDT ) Permalink
Thursday May 19, 2005
Blinkin' Blog I haven't been blogging here frequently as of late. I've been really busy with work; too busy to blog, ironically. So I tend to post things here that've been on my mind for a while. I don't have any rules about it per se, it's just been my modus operandi in recent daze.
As an experiment, I've been blogging my brief whims into ecto (a stolen moment on BART may be my best opportunity to blog). The ecto posts have been going to another blog on blogger, I think the blogger API implementation on this old version of roller is busted, I gave up using ecto with it. I don't know if I'll maintain a separation of ideas that've had a gestation period from passing fancies, but for now that's how it is.
At least the markup and CSS on the other blog are a lot tidier than the one here. I'll have to upgrade this roller implementation soon.
blink blog technorati ecto bart roller
( May 19 2005, 10:29:43 PM PDT ) Permalink
Wednesday May 18, 2005
Sad Mac You know you're working too hard when your computer just starts falling apart under your fingers.
I've gotta make a trip to the Apple Store, I've been using the left side of my left shift key almost a week since the right side collapsed. It's a sad sad Mac.

I'm ditching work tomorrow, making my powerbook happy again and then... I'm gonna chill.
powerbook apple technorati chill
( May 18 2005, 05:11:44 PM PDT ) PermalinkThe Goats Are Back In Town 'member the adverts for Berkeley Farms Milk? "Cows in Berkeley?" Well, yesterday there were goats in Lafayette. At least in my secluded corner of it.
We've had the winter that never seems to leave; it's the month of May and the creekbed in the back of the house, the one that should be down to a trickle, is still gurgling. The stints of warm weather between the storm systems have made for almost tropical conditions (hint to my boss: I'd still take that break in Kauai, were it handed to me). The earth is teeming with flora... or maybe they're just weeds (yep).
It's the time of year when the weed whackers are whacking and leaf barrels are brimming. But instead of hiring a legion of landscapers to clear the hillside across the street from me, the church across the street from me engages the services of goats. Several dozen of them, perhaps over a hundred, in fact.
Apparently Goats R Us will cordon off areas of land and release their goats on to it to let them.... be goats. The bleating army of horned munching machines made quick work of the hillside. Clearing the ground cover of grass and weeds, nibbling away at the shrubs and getting up on their hind legs to pick at the trees, the goats didn't take long to transform the wild overgrown landscape into one shorn back to earth.

|

|

|
Monday May 16, 2005
Baking Components With Velocity For years I've advocated that heavyweight content generation should be moved out of the CMS and that publishing systems should do most their work asynchronously.
Recently, I've been generating Velocity components that should be evaluated at request-time but have at least some of the values they must work with calculated asynchronously when the component is generated. Here's an example that involves localizable content:
<div class="fubars">
$text.get("fubars.per.second", [ $fubarRate ])
</div>
So let's say the ResourceBundle has a key in it for fubars.per.second like so
fubars.per.second=Number of Fubars Per Second: {0}
If all of the calculation is done at request time, MessageTool would do its thing and this would Just Work. However, if $fubarRate is part of a heavier weight calculation that is done offline, we have to set it. So this is where I use Velocity to generate Velocity code:
#set($fr = '#set($fubarRate = ')
#set($fr = "${fr} $measurement.fubarRate)")
$fr
Notice the use of single quotes and double quotes to get the right combination of literal and interpolated evaluation. If my measurement object has a fubarRate property set to 42 then the last line simply outputs
#set($fubarRate = 42)and later, after the generated component gets its request time evaluation, the display is rendered as
<div class="fubars"> Number of Fubars Per Second: 42 </div>
Sure, I could generate my components with the web tier's ResourceBundle to get messages evaluated async as well. This would be 100% baking instead of 90% but it would be bad in other ways:
- It would create a cross dependency between the offline content generation framework and the web code. The ResourceBundle works fine on the web tier, I say leave it there.
- I would have to create another ResourceBundle evaluator for Velocity; MessageTool hooks into struts' plumbing for handling different Locale's, HttpServletRequest's and other container dependencies. Porting it to work outside of the web context seems like a waste of time; let the web tier be the web tier
This separation of baking versus frying ain't new. I advocated it a long time ago in a talk at the O'Reilly Open Source Conference. I was hot on mod_perl and HTML::Mason back then (and, given a Perl environment, I still like them ...but I'd prefer a Java web application environment for i18n hands down), however the same basic ideas hold water using Velocity. At the time, application server misuse was in vogue and hundreds of thousands or even millions of dollars were being poured into "Enterprise Content Management" systems that coupled the CMS functions with those of publishing and request handling. Count that as millions of dollars squandered. There are still people struggling with the legacy of slow and stupid systems that can't be replaced because they spent too much money on it already (yea, what'd Forrest Gump say about stupid?). A few years later, when Aaron Swartz wrote about baking content he was insistent that he didn't care about performance, which is cool. The other benefits of baking that he mentions are perfectly valid. In fact, the publishing system at Salon.com distributes baked goods (HTML::Mason components generated with HTML::Mason components) to the web servers akin to Aaron's call to have something you can just do filesystem operations on. However, that's just the beginning. My maxim is that things that can scale independently should. The users of Bricolage, MovableType and other CMS and blog platforms that separate the management of editorial data, the publish cycle and content serving are enjoying that benefit right now.
java struts velocity i18n l10n CMS Bricolage MovableType mod_perl
( May 16 2005, 11:31:22 AM PDT ) Permalink
Friday May 06, 2005
Ottmar Liebert's blog I just found Ottmar Liebert's blog. He's got an archive that goes back over 11 years! I've long enjoyed his music -- his mix of staccato and graceful classically inspired melodies and textures have always appealed to me; looks like his blog is clueful too and now I've got a new feed to read!
His blog posts cover the gamut of canned food selections at Whole Foods (I've been to that one he shops at in Santa Fe, it's an oasis of good eats), tour dates, instruments, creative commons and tech toys. He's also got an impressive flickr stream. Good to see musicians showing up with a voice other than the one on their recorded works and better to find ones whose repertoire you already dig.
Here are some selections that I'll often have on the 'phones when I'm writing code
 | Viva Ottmar Liebert + Luna Negra |
 | Nouveau Flamenco Ottmar Liebert |
 | Hours... Ottmar Liebert |
Sunday April 24, 2005
Thinking about Microformats and the Hi-Fi Web There is meaning to be derived from the web. But The Semantic Web has little to do with the web itself; it's more about creating parallel universes. The assumption that there must be a separate structure to identify meaning on the web is given by descriptions of The Semantic Web.
HTML has limited ability to classify the blocks of text on a page, apart from the roles they play in a typical document's organization and in the desired visual layout.OK, but those assumptions may be flawed. Yes, often markup is produced that only browsers "understand" to the extent that their responsibility is to render a visual layout. But it doesn't have to be that way.
For instance, right now, many web applications that display user profiles do so in a way that other applications can't understand. The data is flattened in a way that it can't be consumed and meaningfully reused. Perhaps the markup functions properly in web browsers; how the layout elements are identified and therefore stylable for proper display works. But if the markup can't be remarshalled into data, it's low-grade ore. The data becomes markup mojibake. The Semantic Websters say: RDF to the rescue! Just maintain a parallel universe of data! Sure, if the data is marked up in some random ad-hoc fashion without regard to the actual data relationships, it's a problem. Application developers seeking to mine that mis-HTML-ified data are forced to write custom parsers to grok that data. Usually, the remarshalling can't be done losslessly, it's a low-fidelity roundtrip.
Web applications typically do this:

Inside the markup, there is structure and embedded bits of meaning, microformats.
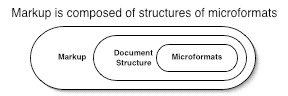
But the round trip is hard. Taking markup and deriving semantic meaning
from document elements usually requires understanding a lot about specific
implementations of data renderings.

The one-web is easy. The two-way web is hard.
When I talk about the one-way web, I'm not referring to protocols, HTTP methods or the "web two dot oh" read-write web. I'm referring to how code handles data to produce pages.
The microformats efforts aim to make the data on the web more understandable, more reusable and therefore more valuable without all of the complexities and problems that pervades The Semantic Web's RDF-centricity. By employing some basic XHTML norms, this data no longer needs to be flattened and lost. A microformat can be embedded in a web page's markup and be remarshalled as data. This is the high fidelity web.
The value of microformats is that your application could already be generating them and you're not even aware of it; there may be data that can be parsed, understood and reused waiting to have value unlocked. The microformat evangelism seeks to make your use of understandable markup intentional (disclaimer: I don't speak for Tantek but I speak with him frequently and I'm just purveying my current interpretation). Whereas microformats are about making the web natively understandable, The Semantic Web is about alternate formats.
When I've read others speak of microformats and alternate formats, I've seen discussion of RSS and Atom thrown in. By definition, these are not microformats, they are alternate formats. Not that there's anything wrong with the existing parallel universes, I just don't want to build more of them. How many goofy XSLT tricks does the world need to go from structured data with yet-another-vocabulary to renderable markup? The microformats answer is zero. Structured blogging looks like more markup mangling to get around, instead of fixing, the crappy user interface tiers of applications; it just doesn't seem necessary.
There's also a lot of interesting things that could be done to specify the intention of links. We'll have to call these nanoformats. They don't refer to data structures or relationships but they can still ascribe more meaning to links.
- Vote Links
- Attempts to indicate whether your reference to something is negative, positive or neutral. I have mixed feelings about this specifically, so I 'spose I should <a rel="vote-abstain"> abstain </a> from further commentary but in general, I like the idea of embellishing a link with intentions.
- nofollow
- Being able to distinguish between intentional links and accidental (i.e. placed not by the page author but some tool or untrusted third party) links is an important element of making the web more meaningful
I think the adoption of hCalendar, hCard (returning to the user profile case above) and the maturation of other microformats holds out the promise of the high fidelity web.
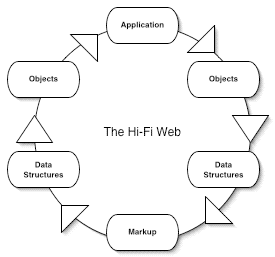
Internal application communications should, of course, do what is expeditious for development and runtime efficiency. But for the web (i.e. the the world wide one), the adoption of markup norms just makes sense. The diffusion of these formats means exercising patience while the web gets more coherent but I find it much more appealing to try solving the problem once in one rendering that the public can consume versus creating yet more parallel universes.
microformats microformat semanticweb web
( Apr 24 2005, 01:41:24 PM PDT ) Permalink
Tuesday April 19, 2005
Technorati as Tech Support: MacOS X update vs. Java This is a true story: an install of the recent MacOS X update bjorked the existing Java installation on a friend's powerbook. Just invoking "java -version" resulted in a lovely little "Segmentation fault." Thank you Cupertino!
A quick search on Technorati returned a pointer to the resolution from a post as the first result. The fix was to reinstall some security updates but the immediacy of the answer is what was really great.
All Hail The Real Time Web! ( Apr 19 2005, 03:01:57 PM PDT ) Permalink
Sunday April 17, 2005
NIN's Open Source Music versus Linus and Larry's metadata propriety I was saddened to read of Larry McVoy's stand on Andrew Tridgell's BitKeeper client development (I like Larry, BitKeeper, etc... which is what makes this tough) and the attacks from Linus Torvalds that followed. Contrast this with Trent Reznor.
What's the connection? The source data for Nine Inch Nails' new single, "The Hand That Feeds" is available to download and muck with in GarageBand. This is a very different attitude about openness and derivative works.
From Make:
"For quite some time I've been interested in the idea of allowing you the ability to tinker around with my tracks -- to create remixes, experiment, embellish or destroy what's there," Reznor says. Here's a screenshot of it on my Mac (View image) and here's where to get it (70MB file). Here are a couple of the first remixes!This came via Joi Ito and he aptly nails it (no pun will go unpunned!):
"Now if only they would put some kind of Creative Commons license on it, it would be perfect."
| I'd prefer that BitMover focused more on innovating the platform (perhaps "application lifecycle management" is excessively hi-falootin but it's not freakishly off-base), there's a lot of room for SCM products to add value or integrate with other pieces adding value elsewhere in the application development chain. Closing the door to third party client innovation is a failure of imagination. Larry is pretty much counting on his internal team (talented though they may be), to be wiser than the community at large about how clients should function, how product specification should interoperate with SCM, how bug and issue tracking should work with SCM, etc. Open client development and derivative works is where it's at. It seems like no new service these days is launched without providing some kind of REST API (I just started checking out recently emerged Upcoming yesterday, the API issue is on page one). The ubiquity of Creative Commons is an undenialable force. Well, I'm not on Larry's case per se, I do admire the guy but the absence of cluetrain savvy is disappointing nonetheless. |

|
Maybe in my copious spare time I'll figure out how to have some fun with GarageBand.
creativecommons nin linus linux bitkeeper garageband
( Apr 17 2005, 09:21:07 AM PDT ) Permalink
Saturday April 16, 2005
Cherry Blosson Festival: The Japanese Equivalent of Oktoberfest I hear from my colleagues in Tokyo that the Cherry Blossom Festival is a Big Deal.
If a picture is worth a thousand words, here's a volume.
( Apr 16 2005, 07:56:15 AM PDT ) Permalink
Wednesday April 13, 2005
Local Search Heating Up While the web seemingly spans all geographical boundaries and has created unprecedented marketplaces, I'll bet that given a choice, you'd rather do business within your community. Looks like the search engines will facilitate that as well.
Yahoo! Local is ramping up their play. They're offering the moms-and-pops free storefront websites. The hosted site gets highlighted placement in their local listing. Doesn't look like it integrates with their domain registration service but that seems like a logical development to expect. Hopefully, they'll spif up the listing's interface, Google's has a cleaner layout with a map front and center. It does the whole Ajax dance to bring up satellite photos of the area. But if there's a coup de grace from Google, it may be Google Local for Mobile Phones.
Blogging proximity will certainly play a role in the marketplaces of the future (though I'm not sure what). There are all kinds of ways for folksographies to be expressed: locations, venues and coordinates. I'm pondering ways to correlate venues with spatial tags because while virtual communities will continue to evolve free of the constraints of space, I'm convinced that sooner or later the next generation of search will bring it all home.
( Apr 13 2005, 11:30:42 PM PDT ) Permalink


![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")