What's That Noise?! [Ian Kallen's Weblog]
 Monday February 13, 2006
Monday February 13, 2006
URL.hashCode() Busted? I did a double take on this:
HashSet set = new HashSet();
set.add(new URL("http://postsecret.blogspot.com"));
set.add(new URL("http://dorion.blogspot.com"));
for (Iterator it = set.iterator(); it.hasNext();) {
System.out.println(it.next());
}
I was expecting to get output like
http://postsecret.blogspot.com http://dorion.blogspot.comor
http://dorion.blogspot.com http://postsecret.blogspot.comBut all that I got was
http://postsecret.blogspot.com
Hmmm....
The java.net.URL javadoc says what I'd expect "Creates an integer suitable for hash table indexing." So I tried this:
URL url1 = new URL("http://postsecret.blogspot.com");
URL url2 = new URL("http://dorion.blogspot.com");
System.out.println(url1.hashCode() + " " + url1);
System.out.println(url2.hashCode() + " " + url2);
and got this
1117198397 http://postsecret.blogspot.com 1117198397 http://dorion.blogspot.comI was expecting different hashCode's. Either java.net.URL is busted or I'm blowing it and my understanding of the contract with java.lang.Object and its hashCode() method is busted. ( Feb 13 2006, 07:37:29 PM PST ) Permalink
Pretty Fly For A White Guy
A common topic of discussion within Technorati is the audience that we serve. We strive to be of service to both the authors (bloggers) and non-bloggers (the blogosphere's newbie readers) alike as well as the advertisers who help pay us. Being generally focused on more geekly topics, I'm oft reminded that my interests are shared only amongst other "middle aged white guys talking about Ruby on Rails" (hey, I'm not that narrow!), but the blogosphere is deep and wide across topics, locales and other demographics.
Yep, even discounting the excess hype aspect, rails is cool. As a matter of fact, I'm pleasantly surprised with the easy read that Agile Web Development with Rails is. Buy it, it's a great book! Unfortunately, it's kind of an academic interest for me at this point. I actually want to reduce the number of programming languages that we're using at Technorati. While it's great to enable developers to contribute to and consume our service oriented architecture with the languages and frameworks that they are most productive in, there's also a battle against degeneration of standards and practices; the blade cuts both ways. Expertise sharing across different programming environments can be difficult and hiring the polylingual programmer is sufficiently challenging already (did I fail to mention that we're hiring?); simplify by constraining is one of the recurrent themes of AWDR's reference to "convention over configuration." In the case of programming language repertoire, less can be more. Anyway, since I'm the only one at Technorati (that I know of) with a rising enthusiasm for Rails, it's unlikely it'll be in use for work stuff anytime soon, bummer. Meantime, I'm just another white guy talking about ruby on rails... JAWGTAROR.
On the topic of who the bloggers are, it's an ever-unfolding story; Dave's State of The Blogosphere is one snapshot into it. Well, I'll be at O'Reilly Emerging Technology Conference's session on data oogling The Data Dump: Fun with Graphs and Charts with some more goodies. The Technorati platform has a rich set of data streams to tap, so this should be fun! See ya in San Diego!
( Feb 13 2006, 09:17:20 AM PST ) Permalink
Wednesday February 08, 2006
BerkeleyDB's "Tied Hash" for Java One of the really wonderful and evil things about Perl is the tie interface. You get a persistent hash without writing a boat load of code. With Sleepycat's BerkeleyDB Java Edition you can do something very similar.
Here's a quick re-cap: I've mentioned fiddling with BerkeleyDB-JE before with a crude "hello world" app. You can use the native code version with Perl with obscene simplicity, too. In years past, I enjoyed excellent performance with older versions of BerkeleyDB that used a class called "DB_File" -- today, the thing to use is the "BerkeleyDB" library off of CPAN (note, you need db4.x+ something for this to work). Here's a sample that writes to a BDB:
#!/usr/bin/perl
use BerkeleyDB;
use Time::HiRes qw(gettimeofday);
use strict;
my $filename = '/var/tmp/bdbtest';
my %hash = ();
tie(%hash, 'BerkeleyDB::Hash', { -Filename => $filename, -Flags => DB_CREATE });
$hash{'539'} = "d\t" . join('',@{[gettimeofday]}) . "\tu\thttp://www.sifry.com/alerts";
$hash{'540'} = "d\t" . join('',@{[gettimeofday]}) . "\tu\thttp://epeus.blogspot.com";
$hash{'541'} = "d\t" . join('',@{[gettimeofday]}) . "\tu\thttp://http://joi.ito.com";
untie(%hash);
Yes, I'm intentionally using plain old strings, not Storable, FreezeThaw or any of that stuff.To prove that our hash was really persistent, we might do this:
#!/usr/bin/perl
use BerkeleyDB;
use strict;
my $filename = '/var/tmp/bdbtest';
my %hash = ();
tie(%hash, 'BerkeleyDB::Hash', { -Filename => $filename, -Flags => DB_RDONLY });
for my $bid (keys %hash) {
my %blog = split(/\t/,$hash{$bid});
print "$bid:\n";
while(my($k,$v) = each(%blog)) {
print "\t$k => $v\n";
}
}
untie(%hash);
Which would render output like this:
541:
u => http://http://joi.ito.com
d => 1139388034903283
539:
u => http://www.sifry.com/alerts
d => 1139388034902888
540:
u => http://epeus.blogspot.com
d => 1139388034903227
Java has no tie operator (that's probably a good thing). But Sleepycat has incorporated a Collections framework that's pretty cool and gets you pretty close to tied hash functionality. Note however that it's not entirely compatible with the interfaces in the Java Collections Framework but if you know those APIs, you'll immediately know the Sleepycat APIs.
com.sleepycat.collections.StoredMap implements java.util.Map with the folloing cavaets:
- It doesn't know how big it is, so don't call the size() method unless you want to see a UnsupportedOperationException
- You can't just abandon
java.util.Iterators that have been working on a StoredMap, you have to usecom.sleepycat.collections.StoredIterator's .close(Iterator) method to tidy up.
So what does the code look like? Well, let's say you wanted to store a bunch of these vanilla beans in the database:
public final class ImmutableBlog implements Serializable {
private static final long serialVersionUID = -7882532723565612191L;
private long lastmodified;
private String url;
private int id;
public ImmutableBlog(final int id, final long lastmodified, final String url) {
this.id = id;
this.lastmodified = lastmodified;
this.url = url;
}
public int getId() {
return id;
}
public long getLastmodified() {
return lastmodified;
}
public String getUrl() {
return url;
}
public boolean equals(Object o) {
if (!(o instanceof ImmutableBlog))
return false;
if (o == this)
return true;
ImmutableBlog other = (ImmutableBlog)o;
return other.getId() == this.getId() &&
other.getLastmodified() == this.getLastmodified() &&
other.getUrl().equals(this.getUrl());
}
public int hashCode() {
return (int) (id * 51 + url.hashCode() * 17 + lastmodified * 29);
}
public String toString() {
StringBuffer sb = new StringBuffer(this.getClass().getName());
sb.append("[id=")
.append(id)
.append(",lastmodified=")
.append(lastmodified)
.append(",url=")
.append(url)
.append("]");
return sb.toString();
}
}
note that it implements java.io.SerializableThis is a class that knows how to persist ImmutableBlogs and provides a method to fetch the Map:
public class StoredBlogMap {
private StoredMap blogMap;
public StoredBlogMap() throws Exception {
init();
}
protected void init() throws Exception {
File dir = new File(System.getProperty("java.io.tmpdir") +
File.separator + "StoredBlogMap");
dir.mkdirs();
EnvironmentConfig envConfig = new EnvironmentConfig();
envConfig.setAllowCreate(true);
Environment env = new Environment(dir, envConfig);
DatabaseConfig dbConfig = new DatabaseConfig();
dbConfig.setAllowCreate(true);
Database blogsdb = env.openDatabase(null, "blogsdb", dbConfig);
Database classdb = env.openDatabase(null, "classes", dbConfig);
StoredClassCatalog catalog = new StoredClassCatalog(classdb);
blogMap = new StoredMap(blogsdb,
new IntegerBinding(), new SerialBinding(catalog,
ImmutableBlog.class), true);
}
public Map getBlogMap() {
return blogMap;
}
}
The majority of the code is just plumbing for setting up the underlying database and typing the keys and values.Here's a unit test:
public class StoredBlogMapTest extends TestCase {
private static Map testMap;
static {
testMap = new HashMap();
testMap.put(new Integer(539),
new ImmutableBlog(539, System.currentTimeMillis(),
"http://www.sifry.com/alerts"));
testMap.put(new Integer(540),
new ImmutableBlog(540, System.currentTimeMillis(),
"http://epeus.blogspot.com"));
testMap.put(new Integer(541),
new ImmutableBlog(541, System.currentTimeMillis(),
"http://www.arachna.com/roller/page/spidaman"));
};
private StoredBlogMap blogMap;
protected void setUp() throws Exception {
super.setUp();
blogMap = new StoredBlogMap();
}
public void testWriteBlogs() throws Exception {
Map blogs = blogMap.getBlogMap();
for (Iterator iter = testMap.entrySet().iterator(); iter.hasNext();) {
Map.Entry ent = (Map.Entry) iter.next();
blogs.put((Integer)ent.getKey(), (ImmutableBlog)ent.getValue());
}
int i = 0;
for (Iterator iter = blogMap.getBlogMap().keySet().iterator(); iter.hasNext();) {
iter.next();
i++;
}
assertEquals(testMap.size(), i);
}
public void testReadBlogs() throws Exception {
Map blogs = blogMap.getBlogMap();
Iterator iter = blogs.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry ent = (Map.Entry) iter.next();
ImmutableBlog test = (ImmutableBlog) testMap.get(ent.getKey());
ImmutableBlog stored = (ImmutableBlog) ent.getValue();
assertEquals(test, stored);
}
StoredIterator.close(iter);
}
public static void main(String[] args) {
junit.textui.TestRunner.run(StoredBlogMapTest.class);
}
}
These assertions all succeed, so assigning to and fetching from a persistent Map works! One of the notable things about the BDB library, it will allocate generous portions of the heap if you let it. The upside is that you get very high performance from the BDB cache. The downside is... using up heap that other things want. This is tunable, in the StoredBlogMap ctor, add this:
// cache size is the number of bytes to allow Sleepycat to nail up envConfig.setCacheSize(cacheSize); // ... now setup the Environment
The basic stuff here functions very well, however I haven't run the any production code that uses Sleepycat's Collections yet. My last project with BDB needed to run an asynchronous database entry remover, so I wanted to remove as much "padding" as possible.
( Feb 08 2006, 12:22:21 AM PST ) Permalink
Monday February 06, 2006
PHP Best Practices, Frameworks and Tools I've annoyed PHP enthusiasts, friends and colleagues alike, with my distaste for PHP. There's nothing intrinsically bad, buggy or poorly performing about PHP per se. It's real simple: a lot of PHP code that I've had to pick up the hood on is a mess and is susceptible to worlds of instability and bugs. The common symptoms I see are mixing business logic, undeclared variables and globals, display code and SQL all scrambled up along with a complete absence of automated tests -- an intractable mess as soon as you want to refactor it. Sorry, my PHP-loving friends, it's nothing personal. I've used PHP longer than most of you. In 1995 or thereabouts it was a refreshing change from Perl CGI's with "print" statements. But now, I frankly don't get all of the zealous passion that PHP proponents have. I'm sure some of the suggestions I've heard ("turn off globals in php.ini", "read Sterling Hughes", "buy PHP 5 Objects, Patterns, and Practice", etc) are all good. I'm sure there are PEAR contributions that are legible and well factored (though, there are those that are not). But all of that misses the point. I'm confident that I or someone else could eventually derive a tool set that meets a rigorous standard for maintainable code. What concerns me are the prevalent practices and establishing best practices. I want to work with the someone else to establish them.
OK. So if it were upto me to establish best practices with PHP, what would I do?
Well, for one, I'd insist on using PHP classes with clear API's. I hate seeing PHP code with a long list of require_once statements, all of which can bring new functions and globals into the current scope. When files are used as grab-bags of functionality, when you're asking yourself "Which included file provided this function or that function? Rewind to read the source code and remember it..." you're in a World of Hurt. Better to define a class, instantiate it or call its static methods. I've been accused of writing PHP code that looks like Java. Well, I'm not sure if that's a disparagement but I think it was intended to be. Thank you very much!
I think PHP has an equivalent to Perl's "use strict" pragma. Gotta have it. Also, I think PHP 5 has exceptions. Gotta have that, too.
I'd use frameworks to encourage a separation of concerns. Either use an existing one or invent one if none of them are upto the task. On my list of things to look into:
The Web Application Component Toolkit project has a somewhat overwhelming list of PHP MVC frameworks. I'm concerned when I see pre-ambles along the lines of "the goal of this project is to port struts to php..." That sounds like a bad idea. Strut's reliance on inheritance and an awkward XML configuration grammar isn't really something to aspire to... I think the Ruby on Rails folks got it right: convention over configuration.I'd insist on unit testing. I don't know anybody using PhpUnit but I'm willing to be convinced that it's good. Tracing without random writes to error_log (or worse) is also a must-have, proper use of log4php is probably the ticket.
What am I missing? What are the best practices when programming with PHP? Any experts with these topics, come talk to me. Technorati is hiring.
php mvc templating web applications unit testing
( Feb 06 2006, 09:14:36 PM PST ) Permalink
Sunday February 05, 2006
Web Two Dot Overload The past few weeks have seen such a saturation of new services, it's mind boggling. The flickr and delicious acquisitions clearly stoked a yodling frenzy (y!a think?). Ya know, it seemed like in months past there were new services every few weeks or so: digg, reddit, memeorandum, personalbee, topix, tailrank, squidoo and on and on and on. But lately, it's hourly.
Now it's megtite, 30boxes, dabble, newroo, wink, tinfinger, podserve and chuquet. Goddamit, TechCrunch has a form to submit your very own web 2.0 venture for coverage. And of course, everyone's variously buzzword compliant with tags, feeds and ajax. Bubble 1.0 was a lot of fun but the sudden thud at the end kinda smarted, didn't it?
pours a glass of two buck chuck
OK, I'm back.
I'm not diss'ing any of these services, there are a lot of really good ideas out there (nor OTOH am I endorsing any). But can they just take a few days off so we can get some work done? How about a moratorium? No more web 2.0 service launches for 48 hours, please! The funny thing is when the content is all self-referential (to the extent that the subject matter is the same or yet-another-new-service); when the services are capturing our artifacts and our artifacts are talking about them... the top story on megtite right now is coComment, on chuquet it's there along with dabble. It's what happens when you point the mic at the P.A. system.
Please, take a few days off. Go skiing or whale watching or something. Or go old school: content is king! e-commerce! woohoo!
web 2.0 moratorium yahoo flickr delicious
( Feb 05 2006, 09:44:39 PM PST ) Permalink
Wednesday February 01, 2006
Large Heap Sizes and OOM Note to self: If you're getting OutOfMemoryError's, bumping up the heap size may actually make the problem worse. Usually, OOM means you've exceeded the JVM's capacity... so you set -Xms and -Xmx to a higher strata of memory allocation. Well, at least I thought that was the conventional wisdom. Having cranked it up to 1850M to open very large data structures, OOM's were still bringing down the house. OK, spread the work around in smaller chunks across multiple JVMs. But it still bombs out. It turns out that you have to be very particular about giving the JVM a lot of heap up front. This set of posts seems to peg it. I'd figured that nailing a big heap allocation was how I'd prevent OOM'ing. Looks like it's time for me to bone up on JVM tuning. I should probably dig into 64-bit Java while I'm at it.
( Feb 01 2006, 11:57:15 PM PST ) Permalink
Sunday January 29, 2006
The Ironies of Blogger Off and on, I've been using a blog on blogger as a link blog and for other "quickies" to post. Tonight, I was closing some browser tabs with stuff I'd been reading about BerkeleyDB (JE) and went to post them here with ecto.
Strangely, ecto was giving me errors, so I check its console:
Response: Your post has been saved as a draft instead of published. You must go to Blogger.com to publish your post. To prevent these errors in the future, request a review at: http://www.blogger.com/unlock-blog.g?blogID=ABCDE Sorry for the inconvenienceBizarre! So, I go to the "unlock-blog" URL and get this:
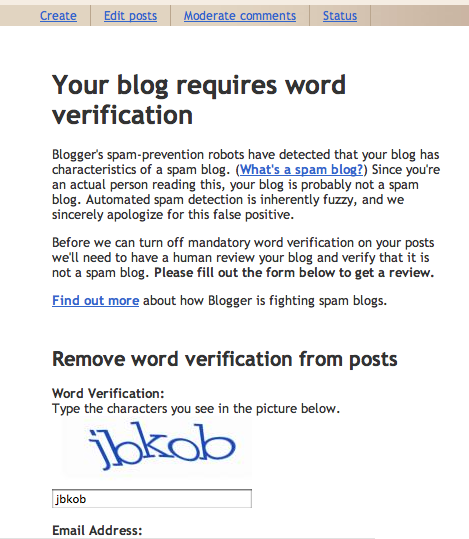
Inconvenience?! The links are to this page that outlines how feeble their anti-spam measures are. They don't have spam-prevention robots, who are they kidding? Will Robinson had a robot. Want to get me started on inconvenience?
The irony here is that it's relatively trivial to produce a list of recently created spam blogs from the blogspot service merely by watching the publish activities on any given day. I do it all of the time. There's a massive amount of spam on that service that percolates up from some simple correlations. And Technorati's index is subsequently scrubbed often on that account. It's a little inconvient. Yet the blogspot people continue to rely on the "Flag As Objectionable" button as their main weapon. Get a clue! Look how trivial to game that system is; I'll surmise that I got googlebowled (bloggerbowled would be more apt) by some dingleberry black hats. Very inconvenient. Given the rampant fraud going on within blogger, it doesn't take a rocket scientist to see.
Google is pretty much operating an open-relay, the blogosphere's equivalent of an SMTP spam-mill, because they lack the imagination to watch their own numbers and their spam rolls out unabated. This has been a ballooning problem for at least a year and a half. It's actually kinda inconvenient. Don't think they haven't been advised. Long before maverick-man coined the term "splog" I'd been sending my friends at the big G data on the extent of their problems. They know.
Dudes, go down the hall and ask the smart people at gmail how they do it. Now I have to go through the blogspot captcha gate instead of using ecto to post on their platform, hardly worth the bother.
Enough of the ironies and inconveniences. On the subject of ecto, please think kind thoughts for Adriaan. I am.
blogspot spam ecto splogs google technorati
( Jan 29 2006, 11:20:57 PM PST ) Permalink
Friday January 27, 2006
Beware the Tiger 10.4.4 Update I finally succumbed to Apple's pleas to update Tiger on my powerbook to 10.4.4. Maven was dumping hotspot errors and Eclipse was misbehaving, so an update seemed in order. Well, when the system came up, my menu bar items (clock, battery status, wifi status, speaker volume, etc) were gone! The network settings were goofed up and I had this profound flash of regret that I hadn't done a backup before doing the update.
Thankfully, Mike Hoover and davidx (co-horts at Technorati) were on hand to assist and dig up the following factoid:
- if you've disabled spotlight (yes I had, spotlight don't do nuffin' for me 'cept chew up resources), then the Tiger update may hose things
- The fix was to ditch
/System/Library/CoreServices/Search.bundle - What I did was open a shell and
sudo mv /System/Library/CoreServices/Search.bundle /var/tmp/, then rebooted - Menu bar came back and from the wifi pulldown, I was able to recreate my network settings
apple powerbook java eclipse maven macosx technorati
( Jan 27 2006, 11:39:48 AM PST ) Permalink
Thursday January 26, 2006
Test Dependencies versus Short Test Cycles A lightweight build system should be able to run a project's test harness quickly so that developers can validate their work and promptly move on to the next thing. Each test should, in theory, stand alone and not require the outcome of prior tests. But if testing the application requires setting up a lot of data to run against, the can run into a fundamental conflict with the practical. How does it go? "The difference between theory and practice is different in theory and in practice."
Recently I've been developing a caching subsystem that should support fixed size LRU's, expiration and so forth. I'd rather re-use the data that I already have in the other test's data set -- there are existing tests that exercise the data writer and reader classes. For my cache manager class, I started off the testing with a simple test case that creates a synthetic entity, a mock object, and validates that it can store and fetch as well as store and lazily expire the object. Great, that was easy!
What about the case of putting a lot of objects in the cache and expiring the oldest entries? What about putting a lot of objects in the cache and test fetching them while the expiration thread is concurrently removing expired entries? Testing the multi-threaded behavior is already a sufficient PITA, having to synthesize a legion of mock objects means more code to maintain -- elsewhere in the build system I have classes that the tests verify can access legions of objects, why not use that? The best code is the code that you don't have to maintain.
<sigh />
I want to be agile, I want to reuse and maintain less code and I want the test harness to run quickly. Is that too much to ask?
My take on this is that agile methodologies are composed of a set practices and principles that promote (among other things) flexible, confident and collaborative development. Working in a small startup, as I do at Technorati, all three are vital to our technical execution. I have a dogma about confidence:
- confidence
- Testing is where the rubber meets the road. Making a change and then putting your finger to the wind will not suffice. Internal improvement of the implementations, refactoring, are a thrice-hourly activity. Test driven development (TDD) is essential to confidently refactoring (internal implementations) and making alterations to the external interface. Serving this principle is a vital practice: automation. If testing consists of a finger to the wind, a manual process of walking through different client scenarios, it won't get done or it won't get done with sufficient thoroughness and the quality is guaranteed to lapse. Testing should come first (or, failing that, as early as possible), be automated and performed often, continuously. If tests are laborious and time consuming, guess what? People won't run them. And then you're back in wing-and-a-prayers-ville.
Lately I've been favoring maven for build management (complete with all of it's project lifecycle goodies). Maven gives me less build code to maintain (less build.xml stuff). However, one thing that's really jumped in my way is that in the project.xml file, there's only one way and one place to define how to run the tests. This is a problem that highlights one of the key tensions with TDD: from a purist standpoint, that's correct; there should be one test harness that runs each test case in isolation of the rest. But in my experience, projects usually have different levels of capability and integration that require a choice, either:
- the tests require their own data setup and teardown cycles, which my require a lot of time consuming data re-initialization ("drop the database tables if they exist", "create the database tables", "populate the database tables", "do stuff with the data")
- tests can be run in a predictable order with different known data states along the way
OR
I ended up writing an ant test runner that maven invokes after the database is setup. Each set of tests that transitions the data to a known state lays the ground work for the next set of tests. Perhaps I'd feel differently about it if I had more success with DBUnit or had a mock-object generator that could materialize classes pre-populated with desired data states. In the meantime, my test harness runs three times faster and there's less build plumbing (which is code) to maintain had I adhered to the TDD dogma.
ant maven tdd refactoring unit testing agile java technorati
( Jan 26 2006, 06:58:22 PM PST ) Permalink
Wednesday January 25, 2006
HTML in the Real World Google has a study of how HTML is really being used out in the wild. They've posted their results, Web Authoring Statistics
December 2005 we did an analysis of a sample of slightly over a billion documents, extracting information about popular class names, elements, attributes, and related metadata. The Good, The Bad and The Ugly: it's all in there.A billion documents sampled, nice!
I think this is a demonstration of Google's expanding interest in grokking the semantics of that are latent in document structures. The results are broken down by
- Pages and elements
- Elements and attributes
- Classes (class="")
- HTTP headers
- Page headers, head element contents
- Metadata, meta tag contents
- The body element
- Text elements
- Table elements
- Link relationships (rel/rev)
- The a element
- The img element
- Scripting: The <script> element
- Editors and their custom markup
I'd love to see how the data changes over time. I suspect parts of the web are becoming more orderly (web 2.0 applications are likely using well formed document structures) while the web as a whole is probably atrophying (the vast installation base of crappy or misconfigured tools are likely the preponderant generators of markup). I'm anticipating a lot of interesting data emerging as the ascendance of microformats continues. Goog, looking forward to follow-up surveys!
( Jan 25 2006, 06:37:29 AM PST ) Permalink
Tuesday January 17, 2006
Transparent Division of JDBC Reads and Writes in MySQL To scale the SQL query load on a database, it's a common practice to do writes to the master but query replication slaves for reads. If you're not sure what that's about and you have a pressing need to scale your MySQL query load, then stop what you're doing and buy Jeremy Zawodny's book High Performance MySQL.

When the state of the readOnly flag is flipped on the ReplicationConnection, it changes the connection accordingly. It will even load balance across multiple slaves. Where a normal JDBC connection to a MySQL database might look like this
Class.forName("com.mysql.jdbc.Driver");
Connection conn = DriverManager.
getConnection("jdbc:mysql://localhost/test", "scott", "tiger");
You'd connect with ReplicationDriver this way
ReplicationDriver driver = new ReplicationDriver();
Connection conn =
driver.connect("jdbc:mysql://master,slave1,slave2,slave3/test", props);
conn.setReadOnly(false);
// do stuff on the master
conn.setReadOnly(true);
// now do SELECTs on the slaves
and ReplicationDriver handles all of the magic of dispatching. The full deal is in the Connector/J docs, I was just pleased to finally find it!
I know of similar efforts in Perl like DBD::Multiplex and Class::DBI::Replication but I haven't had time or opportunity. Brad Fitzpatrick has discussed how LiveJournal handles connection management (there was a slide mentioning this at OSCON last August). LiveJournal definitely takes advantage of using MySQL as a distributed database but I haven't dug into LJ's code looking for it either. In the ebb and flow of my use Perl, it is definitely ebbing these days.
mysql database replication jdbc perl DBI
( Jan 17 2006, 11:42:09 PM PST ) Permalink
Sunday January 15, 2006
Surfacing Microformats in Firefox Calvin Yu has published his Tails Firefox Extension that will surface the microformats on a page, looks good! The plugin shows the hCals and hCards in a page, he's got a nice screenshot of the hCard renderings. Adding contacts (like Smartzilla) and events would be nice but the plugin could just point at the gateways for contacts and events on Technorati. BTW, for Firefox you can one-click install Technorati search in the browser search box on the Technorati Tools page.
microformats firefox technorati
( Jan 15 2006, 04:29:28 PM PST ) Permalink
Saturday January 14, 2006
Distributed Conversations with Microformats Last summer, Ryan King and Eran Globen blogged about citeVia and citeRel as a means of denoting conversation semantics between blog posts. A good summary and subsequent brainstorming is on the Microformats wiki. The blogosphere is currently rich with implicit distributed conversations. A little explicit microformat boost is, IMNSHO, exactly what's needed to nail the coffin in a lot of the crufty old centralized group systems (like Yahoo!'s and Google's). The future of virtual community is here and it is in conversing with blog posts.
There's a lot of discussion of primary citations and secondary props ("Via") but there's not as much on reply-to semantics except for in a few of Eran's posts. Isn't reply-to central to a conversation? Citations are more bibliographic (like when you're linking for a definition, a quote or to identify a source). On the other hand, conversations are about exchanged replies. This is as old as the Internet. Email clients put Reply-to headers in messages when you reply to them. RFC 850 defined it for NNTP over twenty years ago. Reply-to has been the binding for conversations for years, why stop now? That doesn't mean not to use cite and via, those are cool too but they're orthogonal to conversing and more pertinent to definition, quotation and source identification. I'm not entirely sure how I'd like to use via since it's kinda like citing a cite -- maybe it's not necessary at all. If you think of a via as a degenerative quote, then use quote. For instance, I think this makes sense (but then, I had a few glasses of wine earlier... I might not feel the same way in the morning):
I might agree that <a href="http://theryanking.com/blog/archives/2006/01/08/blogging-while-adult/" rel="reply-to">negative sarcasm</a> happens (and worse) wherever there is <a href="http://en.wikipedia.org/wiki/Anonymity" rel="cite">anonymity</a> it is one of an inductively provable aspect of human nature. Countless discussion boards have failed (and continue to) due to participant anonymity. However, it's also important to weigh in with the benefits of anonymity, would citizens of censored and oppressed societies be able to engage in progressive debate without it? Take a look at the Global Voices' <blockquote cite="http://joi.ito.com/archives/2005/05/23/second_draft_of_anonymous_blogging_guide.html"> <a href="http://cyber.law.harvard.eduglobalvoices/?p=179" rel="cite">Anonymous Blogging Guide</a</blockquote>.Wine bottle is corked now. Does that make sense?
distributedconversation microformats reply-to nntp yahoo google anonymity
( Jan 14 2006, 01:44:44 AM PST ) PermalinkBetter, Faster Technorati Blog Embed
Willie Dixon was built for comfort, Technorati embeds were built for speed!
Here's an inside tip: if you are a Technorati member and you claimed your blog a while ago, you can likely optimize how your Technorati embed is served and thus speed up how fast your page renders. Go to your account page for your first claimed blog (or go through them all one by one and click Configure Blog). Does the blog embed code match what's in your template? Load your blog page and View Source to compare. The old school embed code looked like this:
<script type="text/javascript" src="http://technorati.com/embed/[BLOG-CLAIM-ID].js"> </script>What you'll find on your account page is this:
<script type="text/javascript" src="http://embed.technorati.com/embed/[BLOG-CLAIM-ID].js"> </script>How is this an optimization? Why should you bother updating your blog template from the old to the new style? It's faster! We optimized serving the blog embeds with some additional infrastructure not too long ago. The old way works (built for comfort) but the new one works better (built for speed)!
technorati blog claim willie dixon speed comfort
( Jan 14 2006, 12:23:30 AM PST ) Permalink
Friday January 13, 2006
Technorati Is Hiring Technorati is hiring engineers for the website. You should be expert with PHP (including OO constructs, PEAR libraries, templating and application frameworks -- what works and what doesn't), savvy with XHTML and CSS -- be ready with referencable URLs to demonstrate, experienced with web 2.0 services (i.e. even if you don't blog you podcast or addictively use technorati, flickr, del.icio.us, digg, reddit, rollyo, squiddoo, etc) as well as having programmed in at least one language other than PHP and Javascript. Lotsa bonus points for using microformats and Ruby on Rails!
This position is full time, requires US work eligibility and is on-site (San Francisco, 3rd and Brannan). So, is it you? Check out the job listing and send your resume!
php technorati microformats rubyonrails xhtml css web20
( Jan 13 2006, 01:35:28 PM PST ) Permalink


![[Valid RSS]](/images/valid-rss.png "Validate my RSS feed")